Python(パイソン)のビデオ学習を始めたところだが、応用編でよく出てくる「WEBスクレイピング」が面白そう。WEBスクレイピングとは、インターネットを活用して欲しい情報を自動的に集める技術で、ウェブスパイダーとかウェブクローラーとも呼ばれる。Googleの検索ロボットがクローラーと言われているが、ある意味同様の機能である。
Python(パイソン)のビデオ学習を始めたところだが、応用編でよく出てくる「WEBスクレイピング」が面白そう。WEBスクレイピングとは、インターネットを活用して欲しい情報を自動的に集める技術で、ウェブスパイダーとかウェブクローラーとも呼ばれる。Googleの検索ロボットがクローラーと言われているが、ある意味同様の機能である。
PythonではBeautifulSoup(ビューティフルソープ)を使う。BeautifulSoupは、HTMLとXML文書を解析するためのPythonパッケージで、対象のWEBサイトからHTMLデータを抽出できるため、WEBスクレイピングができる。
WEBスクレイピング
▼UdemyのPython学習ビデオ
上記がPythonでBeautifulSoupを実施している画面。しかし、今の自分にはかなり難易度が高い。なかなか完成のイメージがつかめない。
そこで、まずWEBスクレイピングの動作イメージを掴むため、既存のWEBサービスを調べて試用してみることにした。既存のWEBスクレイピングサービスでは評判のよさそうなoctoparse.jpを試した。
https://www.octoparse.jp/からプログラムをダウンロードして実施。
いきなり警告が表示された。
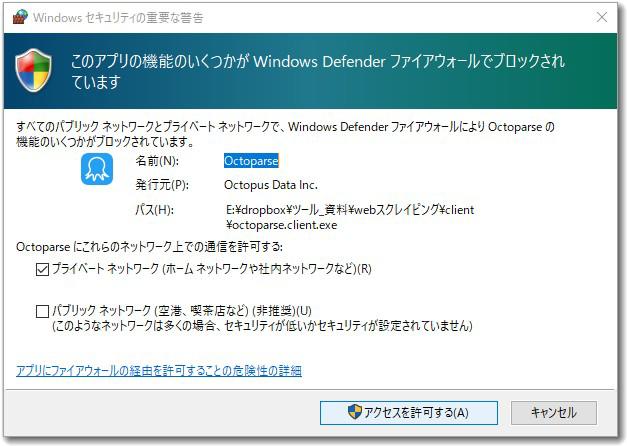
これは、このプログラムがインターネットを介して外部のWEBサーバに接続するため、ウイルス対策ソフトから警告が発せられたものである。ガイドラインでもこの件は明示してあったので、ここでは「アクセスを許可する」とする。
設定を進めていくと、SNSのWEBスクレイピングが面白うそうだった。FacebookやInstagramで特定のユーザーの記事を集めてくることができるようだ。
試しに、自分のInstagramの蕎麦アカウントの情報を収集してみた。
▼インスタグラムの特定ユーザーの記事を読み込む

小一時間ほどかかったが、対象のインスタグラムのアカウントから写真と記事を114件読み込むことができた。
ここまではよかったが、この抽出データをローカルにダウンロード(エクスポート)しようとすると、無料版では不可で有料の上位版にアップグレードが必要だった。
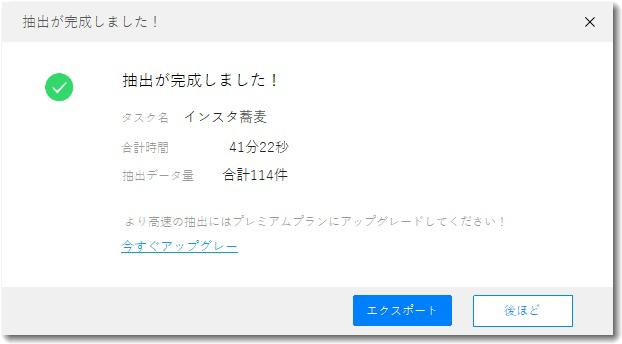
というわけで、いまいち使い勝手がよくないので、このサービスの継続利用は見合わせようと思う。残念。
やはり、きちんと学んでPythonでWEBスクレイピングをやってみろ、ということかもしれない。

この記事を書いた遠田幹雄は中小企業診断士です
遠田幹雄は経営コンサルティング企業の株式会社ドモドモコーポレーション代表取締役。石川県かほく市に本社があり金沢市を中心とした北陸三県を主な活動エリアとする経営コンサルタントです。
小規模事業者や中小企業を対象として、経営戦略立案とその後の実行支援、商品開発、販路拡大、マーケティング、ブランド構築等に係る総合的なコンサルティング活動を展開しています。実際にはWEBマーケティングやIT系のご依頼が多いです。
民民での直接契約を中心としていますが、商工三団体などの支援機関が主催するセミナー講師を年間数十回担当したり、支援機関の専門家派遣や中小企業基盤整備機構の経営窓口相談に対応したりもしています。
保有資格:中小企業診断士、情報処理技術者など
会社概要およびプロフィールは株式会社ドモドモコーポレーションの会社案内にて紹介していますので興味ある方はご覧ください。
お問い合わせは電話ではなくお問い合わせフォームからメールにておねがいします。新規の電話番号からの電話は受信しないことにしていますのでご了承ください。
【反応していただけると喜びます(笑)】
記事内容が役にたったとか共感したとかで、なにか反応をしたいという場合はTwitterやフェイスブックなどのSNSで反応いただけるとうれしいです。
遠田幹雄が利用しているSNSは以下のとおりです。
facebook https://www.facebook.com/tohdamikio
ツイッター https://twitter.com/tohdamikio
LINE https://lin.ee/igN7saM
チャットワーク https://www.chatwork.com/tohda
また、投げ銭システムも用意しましたのでお気持ちがあればクレジット決済などでもお支払いいただけます。
※投げ銭はスクエアの「寄付」というシステムに変更しています(2025年1月6日)
※投げ銭は100円からOKです。シャレですので笑ってください(笑)