いよいよ日本語のGoogle検索エンジンにBERT(バート)が実装された。BERTとはAI研究の世界で昨年注目を浴びた自然言語処理のしくみであり、優れたパフォーマンスを発揮していることで今後の活用方法などが大いに注目されていた。
いよいよ日本語のGoogle検索エンジンにBERT(バート)が実装された。BERTとはAI研究の世界で昨年注目を浴びた自然言語処理のしくみであり、優れたパフォーマンスを発揮していることで今後の活用方法などが大いに注目されていた。
もともと、BERTの開発はGoogleなので、検索エンジンに実装されること自体に違和感はなく、英語版はすでに10月に実装済みだった。全世界70カ国の言語でBERTを導入したことをGoogleが発表したのだが、この対応がとても早くて驚いた。
Googleが公式ツイッターでBERTの導入を発表
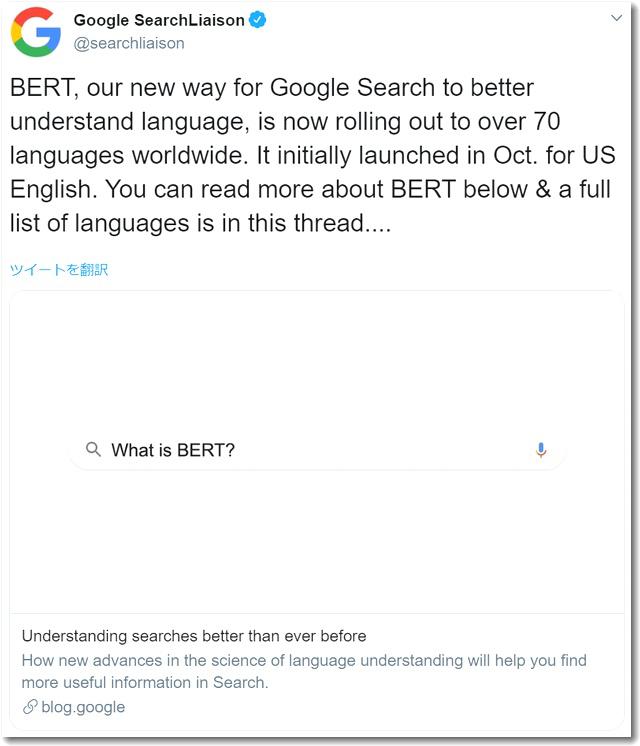
上記のツイッターURLは
https://twitter.com/searchliaison/status/1204152378292867074
さらにツイッター内で言及されているリンクは
https://www.blog.google/products/search/search-language-understanding-bert
である。
このリンク先のページ内容は英語だが、翻訳すると以下のとおり。
15年にわたってGoogle検索で取り組んできたことが1つあるとすれば、人々の好奇心は無限にあるということです。毎日何十億もの検索があり、それらのクエリの15%はこれまで見たことがないクエリです。そのため、予測できないクエリの結果を返す方法を構築しました。
あなたや私のような人が検索に来たとき、クエリを作成するための最良の方法について常に確信があるとは限りません。使用する適切な単語や綴りの方法がわからない場合があります。多くの場合、学習を求めて検索にアクセスするためです。
検索の中核は、言語を理解することです。クエリ内の単語のスペルや組み合わせに関係なく、検索対象を把握し、Webから有用な情報を表示するのが私たちの仕事です。長年にわたって言語理解機能の改善を続けてきましたが、特に複雑なクエリや会話型のクエリの場合、まだ適切に機能しないことがあります。実際、それが人々が「キーワード」を使用する理由の1つであり、私たちが理解すると思うが実際にはどのように質問するかではない単語の文字列を入力します。
機械学習によって可能になった言語理解科学の研究チームの最新の進歩により、クエリの理解方法が大幅に改善され、過去5年間で最大の飛躍を遂げました。検索の歴史で最大の飛躍。
BERTモデルを検索に適用する
昨年、TransformersからのBidirectional Encoder Representationsと呼ばれる、または略してBERTと呼ばれる、自然言語処理(NLP)の事前トレーニングのためのニューラルネットワークベースの手法を導入し、オープンソース化しました。このテクノロジーにより、誰でも独自の最先端の質問応答システムをトレーニングできます。このブレイクスルーは、トランスフォーマーに関するGoogleの研究の結果です。つまり、1つずつ順番にではなく、文の他のすべての単語に関連して単語を処理するモデルです。したがって、BERTモデルは、前後の単語を調べることで単語の完全なコンテキストを考慮することができます。これは、検索クエリの背後にある意図を理解するのに特に役立ちます。
しかし、これを可能にできるのはソフトウェアの進歩だけではありません。新しいハードウェアも必要でした。BERTを使用して構築できるモデルの一部は非常に複雑であるため、従来のハードウェアを使用してできることの限界を押し上げるため、初めて最新のCloud TPUを使用して検索結果を提供し、より関連性の高い情報を迅速に取得します。
クエリをクラックする
それは多くの技術的な詳細ですが、それはあなたにとって何を意味するのでしょうか?まあ、検索のランキングスニペットと注目スニペットの両方にBERTモデルを適用することで、有益な情報を見つけるのに役立つ、はるかに良い仕事をすることができます。実際、結果のランキングに関しては、BERTは検索が米国での英語での検索の10分の1をよりよく理解するのに役立ちます。これは今後、より多くの言語とロケールに反映されます。特に、より長い会話型のクエリ、または「for」や「to」などの前置詞が意味に重要な検索の場合、検索はクエリ内の単語のコンテキストを理解できます。あなたにとって自然な方法で検索できます。
これらの改善を開始するために、変更が実際に役立つことを確認するために多くのテストを行いました。検索の背後にある意図を理解するBERTの能力を実証する評価プロセスを示した例の一部を以下に示します。
「2019年ブラジルへの旅行者はビザが必要です」を検索します。「to」という単語とクエリ内の他の単語との関係は、意味を理解する上で特に重要です。それはブラジル人が米国に旅行することであり、その逆ではありません。以前は、このアルゴリズムはこの接続の重要性を理解していなかったため、ブラジルに旅行する米国市民に関する結果を返しました。BERTを使用すると、Searchはこのニュアンスを把握し、「to」という非常に一般的な単語が実際にここで重要であることを認識でき、このクエリに対してより関連性の高い結果を提供できます。
BERTのなにがいいのか
BERTに馴染みがない一般の方々にとって、Googleの検索アルゴリズムにBERTが導入されてなにがどうなるのかがわかりにくい。
とにかく、BERT自体がよくわからないのではないだろうか。
簡単にBERTの特徴をいうと、「事前学習」と「転移学習」の機能がすごいということだろう。

事前学習とは、文字通り事前にさまざまな文章を飲み込んで学習しておくことで、その後の応用力を格段に高めている。あらゆる学術論文や文豪の小説、およびインターネット上に存在する知識を事前学習しておけば、すばらしい知見が圧縮される。
しかし、事前学習には極めて膨大な情報量の処理が必要である。

を見ると、あるサイズの事前学習にはGPUコンピュータで処理時間が70日かかるという。この膨大な事前処理をしておくことには強力なマシンパワーが必要である。
そして、処理済みの事前学習データを活用するのが転移学習である。
転移学習とは、すでに学習済みのモデルを転用して、新たなモデルを生成する方法のこと。他のデータから学習されたモデルを使うことができるため、少ないデータ・モデルで新たなモデルが生成可能になる。
BERTはこの「事前学習+転移学習」のしくみにより、様々に特化した自然言語タスクに高精度判断の適用が期待できる。
自然言語処理(NLP)×深層学習といえばBERT、というようにどんどん進化していくのではないだろうか。
今後はGoogleの検索結果の変動に注意しつつ、BERT自体を活用していくシーンを創出していくことを検討していきたいと考えている。

この記事を書いた遠田幹雄は中小企業診断士です
遠田幹雄は経営コンサルティング企業の株式会社ドモドモコーポレーション代表取締役。石川県かほく市に本社があり金沢市を中心とした北陸三県を主な活動エリアとする経営コンサルタントです。
小規模事業者や中小企業を対象として、経営戦略立案とその後の実行支援、商品開発、販路拡大、マーケティング、ブランド構築等に係る総合的なコンサルティング活動を展開しています。実際にはWEBマーケティングやIT系のご依頼が多いです。
民民での直接契約を中心としていますが、商工三団体などの支援機関が主催するセミナー講師を年間数十回担当したり、支援機関の専門家派遣や中小企業基盤整備機構の経営窓口相談に対応したりもしています。
保有資格:中小企業診断士、情報処理技術者など
会社概要およびプロフィールは株式会社ドモドモコーポレーションの会社案内にて紹介していますので興味ある方はご覧ください。
お問い合わせは電話ではなくお問い合わせフォームからメールにておねがいします。新規の電話番号からの電話は受信しないことにしていますのでご了承ください。
【反応していただけると喜びます(笑)】
記事内容が役にたったとか共感したとかで、なにか反応をしたいという場合はTwitterやフェイスブックなどのSNSで反応いただけるとうれしいです。
遠田幹雄が利用しているSNSは以下のとおりです。
facebook https://www.facebook.com/tohdamikio
ツイッター https://twitter.com/tohdamikio
LINE https://lin.ee/igN7saM
チャットワーク https://www.chatwork.com/tohda
また、投げ銭システムも用意しましたのでお気持ちがあればクレジット決済などでもお支払いいただけます。
※投げ銭はスクエアの「寄付」というシステムに変更しています(2025年1月6日)
※投げ銭は100円からOKです。シャレですので笑ってください(笑)